In today's digital landscape, content-driven applications need to be ready for anything—from steady daily traffic to sudden viral spikes. For teams using Contentful as their headless CMS, managing these scaling challenges while controlling costs remains a significant hurdle. According to research by Unbounce, 70% of consumers admit that page load speed impacts their willingness to buy from an online retailer, making scalability not just a technical concern, but a business imperative.
This article explores how the Convox Contentful integration creates a powerful solution for scalable, cloud-agnostic deployments—balancing performance needs with infrastructure costs while eliminating DevOps complexity.
Content-rich applications present unique scaling challenges:
Most SaaS-based hosting platforms charge premium rates for scaling resources—especially during traffic spikes—leading to unpredictable monthly costs and difficult budget planning.
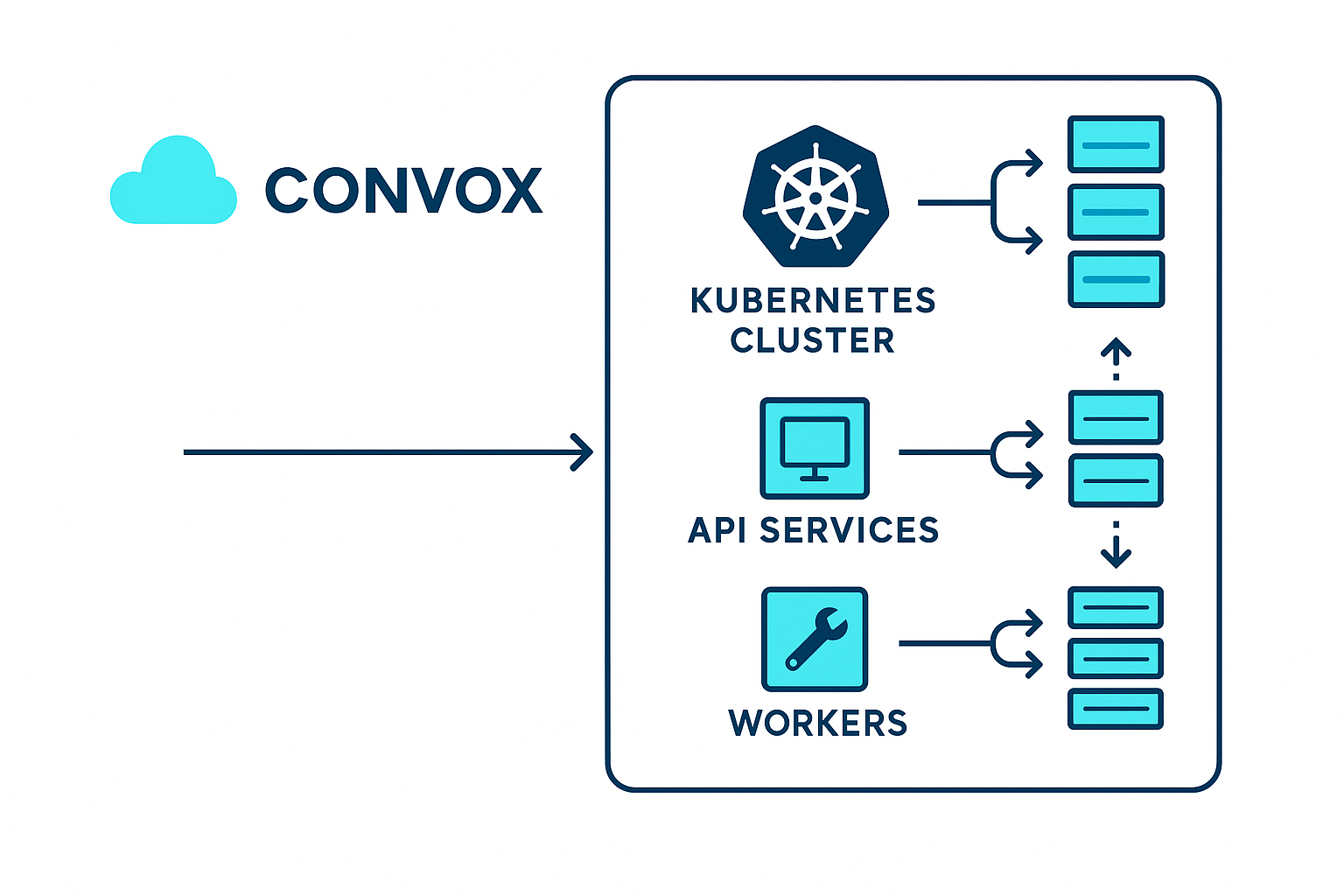
Convox approaches scaling differently by giving you complete control over your infrastructure while abstracting away the complexity. When integrated with Contentful, this creates a powerful publishing-to-deployment pipeline.
At its core, Convox runs on Kubernetes but simplifies the interface through abstraction. Here's how the scaling architecture works:
Let's explore a technical example of how to configure autoscaling for a Contentful-powered application running on Convox.
Consider a content-rich e-commerce platform with the following components:
convox.yml for Scalabilityenvironment:
- CONTENTFUL_SPACE_ID
- CONTENTFUL_ACCESS_TOKEN
- CONTENTFUL_PREVIEW_TOKEN
- NODE_ENV=production
services:
web:
build: ./frontend
port: 3000
scale:
count: 2-10
targets:
cpu: 70
memory: 512
api:
build: ./api
port: 4000
scale:
count: 2-8
targets:
cpu: 75
memory: 1024
worker:
build: ./worker
scale:
count: 1-5
targets:
cpu: 80
memory: 1024
metrics:
agent: true
image: awesome/metricsThis configuration demonstrates:
To further enhance scaling performance, you can configure node groups with specific instance types and scaling parameters. Convox supports defining these configurations using JSON files, which provides more flexibility and improved readability compared to inline configuration.
First, create a JSON file (e.g., node-groups.json) with your custom node group definitions:
[
{
"id": 101,
"type": "c5.large",
"capacity_type": "SPOT",
"min_size": 1,
"max_size": 10,
"label": "web-workers",
"tags": "environment=production,workload=web"
},
{
"id": 102,
"type": "m5.large",
"capacity_type": "ON_DEMAND",
"min_size": 1,
"max_size": 5,
"label": "api-workers",
"tags": "environment=production,workload=api"
}
]Then apply this configuration to your rack:
$ convox rack params set additional_node_groups_config=/path/to/node-groups.json -r rackNameNow, update your convox.yml to target specific node groups:
services:
web:
# previous configuration...
nodeSelectorLabels:
convox.io/label: web-workers
api:
# previous configuration...
nodeSelectorLabels:
convox.io/label: api-workersThis configuration:
For build-specific workloads, you can create a separate JSON file for build nodes (e.g., build-groups.json):
[
{
"type": "c5.xlarge",
"capacity_type": "SPOT",
"min_size": 0,
"max_size": 3,
"label": "app-build"
}
]And apply it with:
$ convox rack params set additional_build_groups_config=/path/to/build-groups.json -r rackName
For even more sophisticated scaling, you can configure your services to scale based on specific CPU and memory metrics:
services:
web:
# previous configuration...
scale:
count: 2-10
targets:
cpu: 70
memory: 80This configuration enables your frontend to scale dynamically based on both CPU utilization and memory consumption:
For more complex scenarios, you might need different metrics for different parts of your application. For example:
services:
web:
scale:
count: 2-10
targets:
cpu: 70
api:
scale:
count: 2-8
targets:
memory: 75
worker:
scale:
count: 1-5
targets:
cpu: 80
memory: 85This approach allows each component to scale based on its resource consumption patterns, ensuring optimal resource utilization.
When a Contentful user publishes new content, the integration with Convox can:
This integration eliminates the traditional friction between content management and DevOps, allowing content teams to publish with confidence knowing that the infrastructure will scale to meet demand.
One of the major advantages of using Convox with Contentful is cost control. Unlike SaaS-based hosting platforms that charge premium rates for scaling, Convox allows you to:
By deploying on your own cloud account, you avoid the markup that SaaS platforms add to basic cloud resources. This often results in 30-50% lower infrastructure costs for the same performance capacity.
Based on industry experience, here are key best practices to follow:
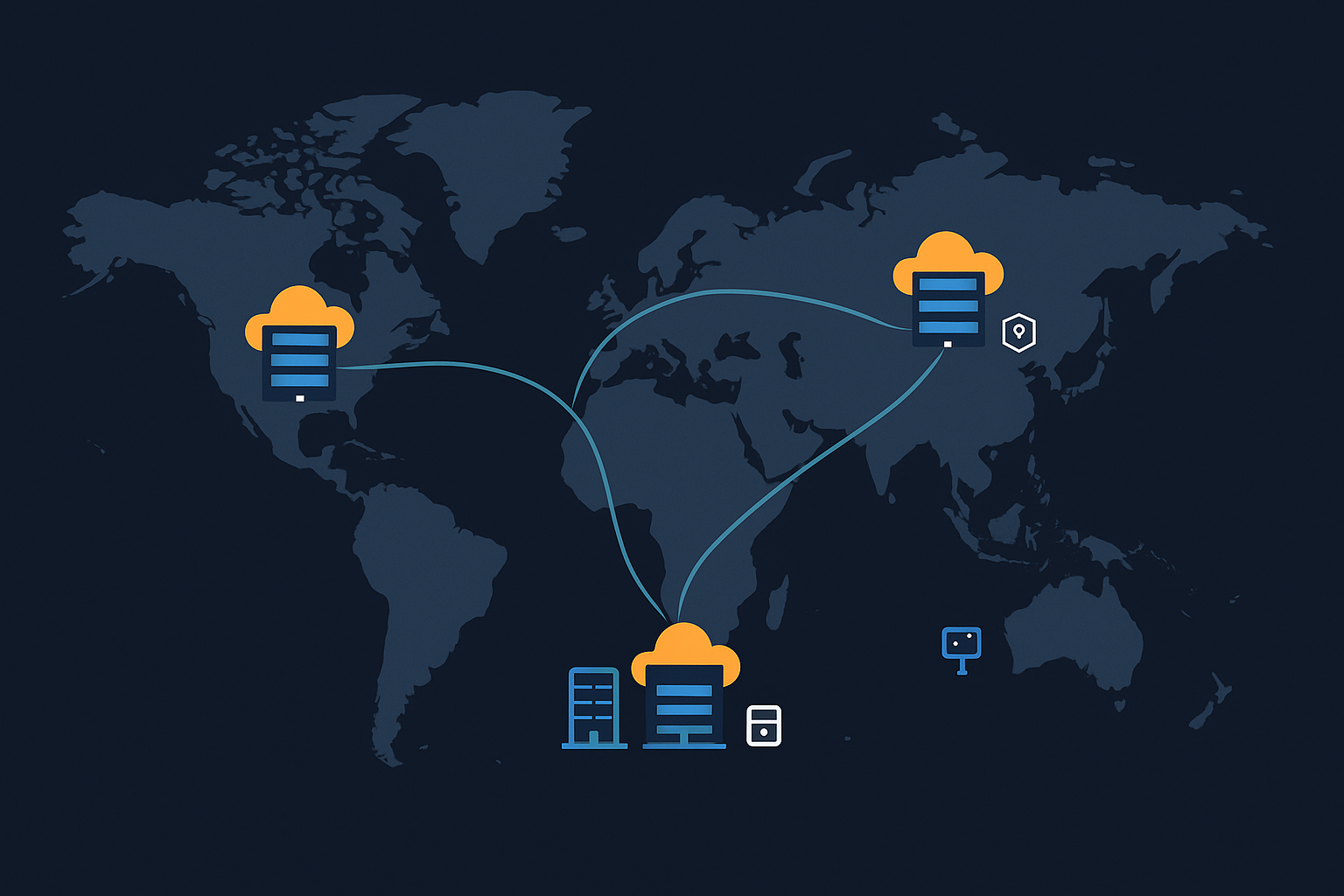
For applications with a global audience, you can deploy multiple Convox racks in different regions and use a global load balancer to route traffic to the nearest region.
2. Once your racks are installed, deploy your application to each rack using the CLI:
$ convox apps create myapp -r my-org/eu-rack
$ convox apps create myapp -r my-org/us-rack
$ convox apps create myapp -r my-org/ap-rack
# Deploy to each rack
$ convox deploy -r my-org/eu-rack
$ convox deploy -r my-org/us-rack
$ convox deploy -r my-org/ap-rack3. Configure a global load balancer (like AWS Global Accelerator or Cloudflare) to route traffic to the nearest regional endpoint.
This architecture delivers content with minimal latency regardless of the user's location while still providing the scaling benefits of Convox.
The integration of Convox with Contentful creates a powerful platform for deploying scalable, content-driven applications. By combining Contentful's content management capabilities with Convox's infrastructure flexibility and scaling options, teams can:
For digital agencies, e-commerce platforms, media publishers, and SaaS companies managing content-rich applications with unpredictable traffic patterns, this integration offers the ideal balance of performance, flexibility, and cost-efficiency.